The new shape of code review
As teams start landing more AI-generated code, the review process has to evolve. The old model doesn’t scale — you can’t 3–5x your code throughput while keeping the same human review bandwidth without something breaking.
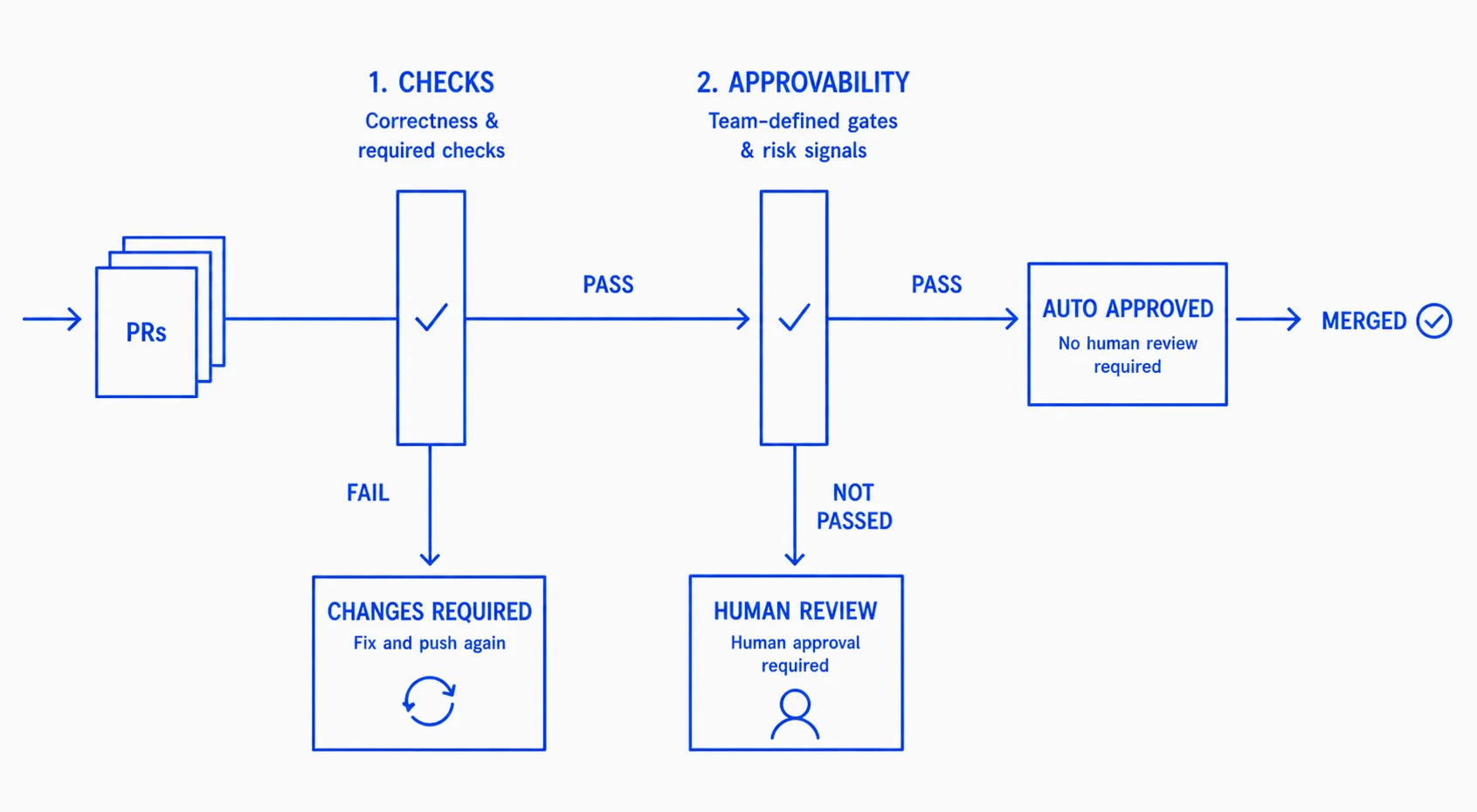
A more realistic model looks like this:
- AI verifies correctness
- AI approves low-risk changes
- Humans review architecture and design
This isn’t theoretical. Teams are already moving in this direction — not because it’s elegant, but because they have to.
Step 1: AI verifies correctness
This is the obvious part. AI is already very good at catching edge cases, enforcing conventions, tracing logic across files, and surfacing issues humans would miss in a quick pass.
That replaces a huge portion of what reviewers spend their time on today. Not perfectly — but consistently.
Step 2: AI decides what doesn’t need review
This is the more interesting shift.
Not every PR deserves human attention. Some changes are low risk, well understood, tightly scoped, and consistent with existing patterns. Today, those still go through the same process: request review, wait in queue, get a quick “LGTM.” That’s where most of the time gets wasted.
The better question isn’t “is this code correct?” — it’s “does this PR actually require a human?” That’s a different problem, and it turns out to be a very useful one.
What approvability actually does
At a high level, approvability evaluates a pull request and determines whether it can safely bypass human review. But it’s not a fixed decision. Teams define what “safe” means, and you set the gates.
In practice, those gates look like:
- Feature flags. Client-facing feature behind a flag that’s 100% off → auto-approve. Enabled only for employees testing in prod → low risk, auto-approve.
- Author trust. Trusted owner modifying their own area → eligible for auto-approval. New contributor in a sensitive area → always require review.
- Surface area. Docs changes, marketing site updates, small scoped diffs → likely safe.
- Critical paths (hard blocks). Payments, auth, core infrastructure → never auto-approve.
The goal isn’t just to find issues. It’s to encode your team’s risk tolerance directly into the system.
What this unlocks
Once you can reliably identify low-risk changes, a few things follow:
- The review queue shrinks. Fewer PRs competing for attention. Faster turnaround on the ones that matter.
- Human attention gets reallocated. Less time on formatting and small diffs. More time on architectural decisions.
- Throughput increases without adding reviewers. Some teams are auto-approving 20–30% of PRs with no extra meetings or process.
- Reviews become more intentional. If a human is involved, it’s for a reason — not just because every PR needs a review.
Tiered review in practice
This doesn’t look like blind auto-merge. It looks more like a tiered system:
- Low-risk PRs → auto-approved or lightly gated
- Medium-risk PRs → AI-assisted review + human skim
- High-risk PRs → deep human review
One uniform process becomes three calibrated ones.
Where this is going
As more code gets generated by agents, the bottleneck keeps moving. First it was writing code. Then it was reviewing code. Now it’s deciding what deserves attention at all.
You don’t want humans in the loop for everything. You want them in the loop for the right things. That’s why approvability matters — it’s not just about saving time on small PRs. It’s about building a system where machines handle the bulk of verification, machines filter what’s important, and humans focus on decisions that shape the system.
Code review doesn’t disappear. It becomes more selective, more opinionated, and more aligned with how software is actually built in an agent-driven world.